Adversarial Active Exploration for Inverse Dynamics Model Learning
|
National Tsing Hua University, Hsinchu
|
|
Conference on Robot Learning (CoRL) 2019 (oral)
|
Abstract
We present an adversarial active exploration for inverse dynamics model learning, a simple yet effective learning scheme that incentivizes exploration in an environment without any human intervention. Our framework consists of a deep reinforcement learning (DRL) agent and an inverse dynamics model contesting with each other. The former collects training samples for the latter, with an objective to maximize the error of the latter. The latter is trained with samples collected by the former, and generates rewards for the former when it fails to predict the actual action taken by the former. In such a competitive setting, the DRL agent learns to generate samples that the inverse dynamics model fails to predict correctly, while the inverse dynamics model learns to adapt to the challenging samples. We further propose a reward structure that ensures the DRL agent to collect only moderately hard samples but not overly hard ones that prevent the inverse model from predicting effectively. Experimental results show that our method is comparable to those directly trained with expert demonstrations, and superior to the other baselines even without any human priors.
Overview
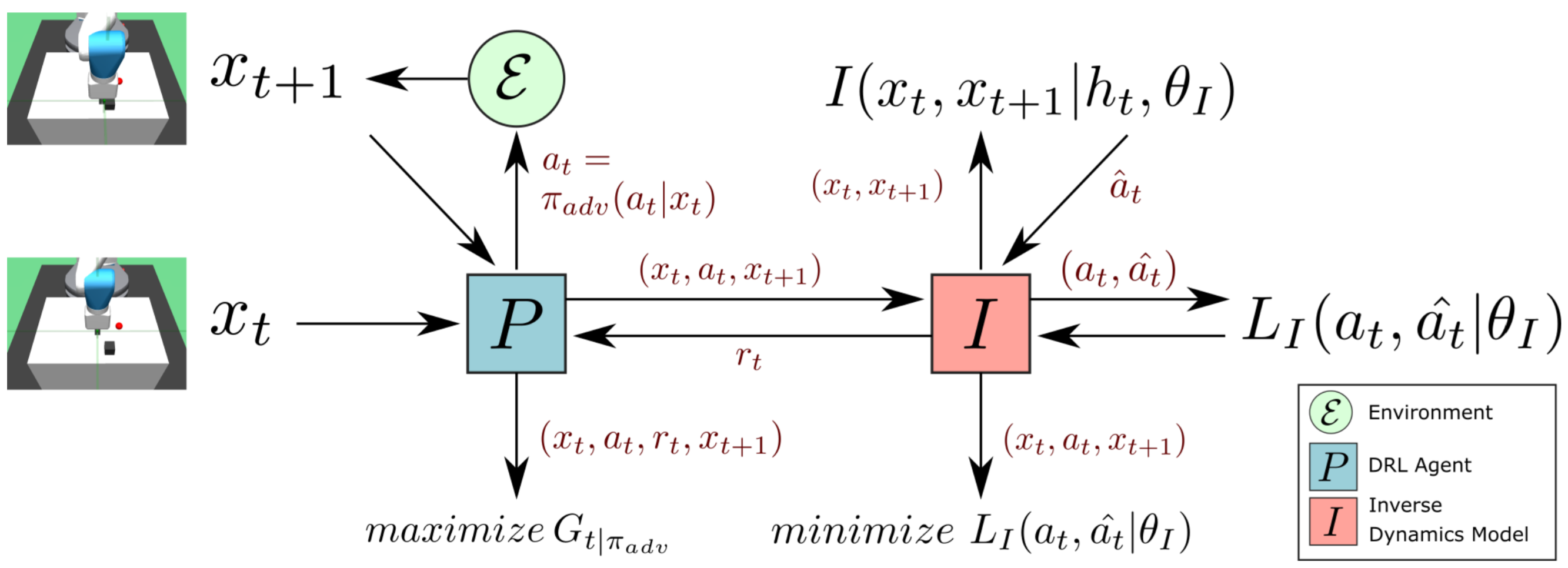
We implement the proposed method by jointly training a deep reinforcement learning (DRL) agent and an inverse dynamics model competing with each other. The former explores the environment to collect training data for the latter, and receives rewards from the latter if the data samples are considered difficult. The latter is trained with the data collected by the former, and only generates rewards when it fails to predict the true actions performed by the former. In such an adversarial setting, the DRL agent is rewarded only for the failure of the inverse dynamics model. Therefore, the DRL agent learns to sample hard examples to maximize the chances to fail the inverse dynamics model. On the other hand, the inverse dynamics model learns to be robust to the hard examples collected by the DRL agent by minimizing the probability of failures. As a result, as the inverse dynamics model becomes stronger, the DRL agent is also incentivized to search for harder examples to obtain rewards.
Algorithm
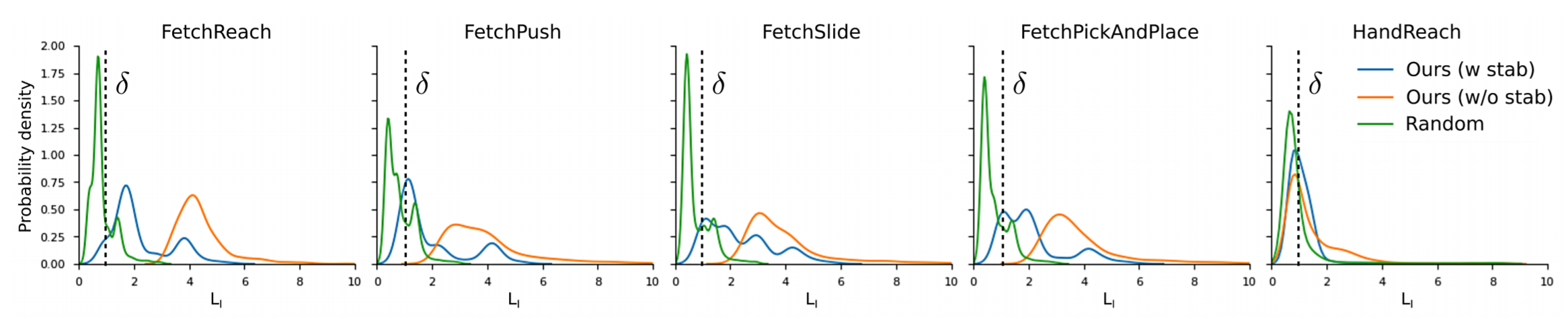
Experimental Result
Citation
@inproceedings{hong2019self-adv,
author = {Zhang-Wei Hong and Tsu-Jui Fu and Tzu-Yun Shann and Yi-Hsiang Chang and Chun-Yi Lee},
title = {Adversarial Active Exploration for Inverse Dynamics Model Learning},
booktitle = {Conference on Robot Learning (CoRL)},
year = {2019}
}
template from pathak22